ORIGINAL RESEARCH
Optimization of Health Service Utilization Among Elderly People With Chronic Diseases in Rural Ethnic Minorities in Northwest Yunnan Using Graph Neural Networks
Jing Zhang, MD and Haitao Fan, MD
and Haitao Fan, MD
School of Health and Wellness, Yunnan Technology and Business, University, Kunming City, China
Keywords: Ethnic minority areas, health service utilization, multimorbidity elderly, service path optimization
Abstract
Background: The demand for health services among elderly patients with chronic diseases in rural ethnic minority areas of northwest Yunnan is increasing. Yet, service utilization remains imbalanced. Existing studies mainly focus on disease combinations, overlooking temporal and spatial variations in medical behavior.
Methods: This study applies graph neural networks to construct a heterogeneous graph integrating patients, medical institutions, and geographic units, modeling dynamic service paths to identify high-frequency and potentially lost-contact patients. Using a heterogeneous graph attention network for feature embedding and a graph attention network classifier, the model captures behavioral similarity and service path patterns. Geographic and social variables such as ethnicity, terrain, and road accessibility further enhance sensitivity to regional disparities.
Based on node centrality and path distribution, targeted service optimization strategies—such as mobile medical points and cross-regional collaboration nodes—are proposed for resource allocation.
Results: Experimental results reveal marked spatial and structural disparities: Diqing Prefecture shows an accessibility index of 68 min versus 29 min in Dali; multimorbidity (3+) groups have a 68.6% matching rate but a 1.138 utilization rate, indicating resource imbalance; and mountain unit G18’s coverage index is only 0.31.
Conclusion: The proposed model achieves a Macro-F1 of 0.83, outperforming XGBoost (0.76), effectively identifying high-risk groups, locating service bottlenecks, and supporting precise health resource optimization.
Citation: Blockchain in Healthcare Today 2025, 8: 436 - https://doi.org/10.30953/bhty.v8.436
DOI: https://doi.org/10.30953/bhty.v8.436
Copyright: © 2025 The Authors. This is an open-access article distributed in accordance with the Creative Commons Attribution Non-Commercial (CC BY-NC 4.0) license, which permits others to distribute, adapt, enhance this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0. The authors of this article own the copyright.
Submitted: July 31, 2025; Accepted: November 4, 2025; Published: December 15, 2025
Competing interests and funding: The authors declare that they have no financial conflicts of interest.
Project of Scientific Research Fund of Yunnan Provincial Department of Education (2025J1328).
Corresponding Author: Jing Zhang, Email: yngs_1591249@hotmail.com
As the growth of an aging population intensifies, chronic diseases—especially multimorbidity—have become the major health burden among the elderly. According to the Report on the Nutrition and Chronic Disease Status of Chinese Residents (National Health Commission, 2020), coexisting chronic diseases not only increase health risks but also place greater pressure on the healthcare system.1,2
Patients with multimorbidity often experience poor treatment continuity and fragmented service pathways, challenging the coordination of primary care. In rural China, where the elderly population is large and rapidly growing, limited resources, inconvenient transportation, and low service accessibility exacerbate service mismatches and health risks.3–6
Northwest Yunnan (Figure 1)—comprising Dali, Lijiang, Diqing, and Nujiang—features complex terrain, ethnic diversity, and an underdeveloped healthcare system, leading to a high prevalence of chronic comorbidity. Existing studies remain largely static and lack systematic modeling of service paths and behavioral heterogeneity.7,8 Therefore, new approaches integrating behavioral pattern mining and spatial network analysis are urgently needed to identify high-risk groups, locate bottlenecks, and optimize health resource allocation for improved equity and efficiency.

Fig. 1. Northwest Yunnan—comprising Dali, Lijiang, Diqing, and Nujiang.
With the development of society, research on chronic disease comorbidity has increased, especially in the areas of epidemiological statistics, disease combination patterns, and factors affecting medical behavior.9,10 However, there are two significant limitations in the reported results of research. First, comorbidity analysis focuses on the types of elderly diseases themselves and often uses co-occurrence frequency or cluster analysis to divide comorbidity patterns.11,12 This ignores the characteristics of patients’ medical behavior in the time dimension, such as frequency of visits, intervals, referral trajectories, and other temporal factors. Second, there is a lack of systematic modeling of social structural variables that affect service utilization.
The spatial interaction relationship between geographical location, traffic accessibility, and medical institution networks is often simplified.13,14 This fails to explain the structural constraints behind service accessibility. Therefore, when dealing with a geographically closed region like northwest Yunnan, which has significant differences in ethnicity, traditional methods struggle to fully characterize the complex relationship between individuals and systems.
Most related studies are based on questionnaire surveys or health statistics, using traditional methods such as statistical regression models, multivariate analysis of variance, and structural equation models to analyze comorbidities and their relationship with health service utilization.15,16 These studies yield certain results in identifying the factors that influence service utilization. They are insufficient in dealing with complex system structures, such as dynamic, heterogeneous, and spatially interactive ones. In particular, conventional analysis methods struggle to identify potential high-risk elderly populations and optimize service paths, as they cannot achieve data-driven intelligent reasoning and prediction and fail to model the service path relationships between individuals and institutions at the graph structure level.17,18 At the same time, few studies have attempted to apply artificial intelligence methods, especially graph learning models, to address the path dependence of individual behavior, the coupling relationships of multidimensional variables, and the structural characteristics of spatial service networks.
Existing studies reveal that graph neural networks (GNNs) can effectively process graph-structured data with the ability to depict complex relationships between nodes, dynamic paths, and multidimensional feature fusion. The networks demonstrated good performance in social network analysis, recommendation systems, traffic route planning, and other fields. In the field of health services, some scholars have attempted to utilize GNN for electronic health record analysis, disease transmission path modeling, and drug prediction,19,20 achieving certain research results. However, there remains a lack of systematic modeling frameworks based on GNN in the identification of chronic disease comorbidity service pathways and the optimization of service accessibility,21,22 especially in research on the health service network structure for rural elderly groups in ethnic minority areas. This makes it difficult to accurately identify and respond to relevant policy formulation and resource allocation, thereby exacerbating service disparities and structural health inequalities.
In recent years, GNN applications in health informatics have expanded, demonstrating strong potential in electronic health record modeling, disease pathway inference, and drug interaction prediction. For instance, memory-enhanced and transformer-integrated GNNs have been used for personalized medication recommendations and heart failure patient stratification. However, most studies focus on clinical diagnosis or risk prediction, with limited exploration of primary health service utilization in resource-limited, geographically isolated minority regions. This study extends these methods by integrating patients, institutions, and geographic units into a unified heterogeneous graph, capturing both spatial interactions and institutional linkages, thereby addressing a key gap in evaluating healthcare accessibility and equity.
In this article, the authors focus on healthcare service utilization behavior among elderly people with chronic diseases from ethnic minorities in rural areas of northwestern Yunnan Province and construct a modeling framework based on GNN.23 This study integrates patients, medical institutions, and geographical units to construct a heterogeneous graph network and defines edge connections based on medical behavior and spatial proximity. A heterogeneous graph attention network (HAN) is used to extract node embeddings to characterize the behavioral similarities and potential path preferences among patients.24,25 Subsequently, a graph attention classifier is used to identify service utilization patterns and classify frequent patients and potential lost-to-follow-up patients.26 The model further integrates geographical and social variables such as ethnicity, topography, and transportation to improve the responsiveness to healthcare disparities in remote areas.
Based on the output results and graph structure indicators (such as node centrality and path connectivity), suggestions for precise allocation of regional health resources and dynamic optimization of service paths are proposed.27,28
The results reveal significant differences in the structure and space of medical services for ethnic minorities in northwestern Yunnan. The topographic coefficient of the mountain unit G18 reached 1.8, but the coverage rate was only 0.31. The matching rate of multiple disease combinations was only 68.6%, but the utilization rate was as high at 1.138. The accessibility index of Diqing Prefecture was 68 min, which was much higher than that of Dali at 29 min, reflecting the constraints of geographical and transportation factors on medical accessibility.
In addition, the findings provide technical support and a decision-making basis for precision medical intervention and resource optimization in rural and ethnic minority areas29 and expanded the application space of graph learning in the field of public health.
Methods: Health Service Optimization Modeling Path
Building a Heterogeneous Health Service Utilization Graph Network
Definition of node and edge types: To model health service utilization among elderly patients with chronic comorbidities in rural ethnic regions of northwest Yunnan, a heterogeneous graph network was constructed with multiple entity types and relationships. Nodes include patients (P), medical institutions (H), and geographic units (G). Patient nodes represent elderly individuals with chronic comorbidities; institution nodes cover village clinics, township health centers, and county hospitals; and geographic units correspond to township divisions. Each node carries multidimensional attributes such as demographics, health status, spatial coordinates, and accessibility indicators.
Edges are defined by inter-entity relationships: patient–institution (P–H) edges denote medical visits, with weights based on normalized visit frequency; institution–institution (H–H) edges reflect spatial distance and referral links, weighted via a Gaussian kernel; and geographic unit–unit (G–G) edges indicate spatial adjacency. Additionally, patient–geographic unit (P–G) and geographic unit–institution (G–H) edges capture residential affiliation and spatial service linkage, forming a comprehensive representation of the regional health service network.
Graph Structure Construction and Data Mapping Process
The data sources include three parts: outpatient and inpatient medical records from the past 3 years (health information system), spatial location and road data (GIS), and administrative divisions and economic indicators (socioeconomic database). All data were standardized, had missing data filled in, and were linked by primary keys before being uniformly numbered. Medical record data were aggregated into time series by patient, and diagnostic codes were retained for label generation. After the coordinates of medical institutions and geographic units were transformed, spatial distances were calculated using spherical cosine distance to construct spatial correlation edges.
To avoid the skewed distribution of node and edge relationships in heterogeneous networks, an edge sampling strategy is applied to regulate the density of extremely high-frequency edges. The specific method involves performing log compression on the patient-institution edge according to the visit frequency, ensuring that high-frequency medical behavior does not dominate the model learning. The final form of the heterogeneous graph is G = (V, E, T_V, T_E), where V is the set of all nodes, E is the set of edges, and T_V and T_E represent the types of nodes and edges, respectively. To further enhance the network’s semantic expression ability, independent meta-path combinations are designed for different edge types during the graph construction process, such as P-H-P, P-H-H-P, and P-G-H-P. These meta-paths are used to capture cross-type behavioral dependencies and service associations in the subsequent heterogeneous GNN learning process.30,31
Figure 2 illustrates the heterogeneous health service network and node degree distribution of elderly patients with chronic comorbidities in rural ethnic minority areas of northwest Yunnan. The left panel maps patients, medical institutions, and geographic units by spatial coordinates, showing medical visit links (patient–hospital) and referral collaborations (hospital–hospital). Frequent cross-unit visits reveal patient mobility and a mismatch between service supply and demand. The right panel shows node degree distribution, where most patients have degrees of 1–3, while several hospitals exhibit high degrees, indicating central roles, resource concentration, and potential service bottlenecks. This structure underpins subsequent GNN-based analyses for identifying high-risk groups and optimizing service pathways.

Fig. 2. Heterogeneous health service network structure and node degree distribution characteristics.
The focus of this phase is to address the challenge of representing healthcare service behavior data in a multidimensional structure. By clarifying node types and the semantic categories of edges and combining multidimensional features such as time series, spatial distribution, and behavioral paths, the original unstructured healthcare service data are transformed into a graph structure suitable for deep learning modeling.
Embedded Feature Representation Learning
Design of heterogeneous graph attention mechanism: After completing the construction of the heterogeneous graph structure, it is necessary to learn effective feature representations for various nodes in the graph to capture the high-order semantic correlations between patients in terms of service behaviors, geographical distribution, and institutional access paths.32,33 To adapt to heterogeneous graphs with multiple node types and diverse edge structures, this study selected the HAN for node embedding calculations. This method can process information heterogeneity at both the meta-path level and the node adjacency level through a multi-level attention mechanism, generating node representations that are sensitive to semantic relationships. The construction of the meta-path is based on the structure defined in the previous paper. The three types of composite paths, P-H-P, P-H-H-P, and P-G-H-P, are mainly selected, corresponding to the three types of connections: behavioral homogeneity, institutional shared access, and spatial similarity. At the meta-path level semantic fusion layer, an independent semantic attention mechanism is applied to calculate the importance weight for each type of meta-path. Assuming that the embedding vector of a node vi
in the graph under the meta-path type m is, 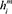 , the semantic attention coefficient is calculated by the following formula:
, the semantic attention coefficient is calculated by the following formula:
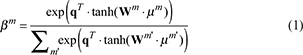
where 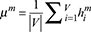 , q is a trainable semantic vector, and Wm is a semantic-specific transformation matrix. This mechanism weightedly aggregates node embeddings in different semantic spaces under multiple meta-paths to generate the final node representation for subsequent classification model input.
, q is a trainable semantic vector, and Wm is a semantic-specific transformation matrix. This mechanism weightedly aggregates node embeddings in different semantic spaces under multiple meta-paths to generate the final node representation for subsequent classification model input.
Figure 3 shows the distribution of different types of nodes in the embedding space after t-Distributed Stochastic Neighbor Embedding (t-SNE) dimensionality reduction. The X and Y axes represent the principal component dimensions extracted by t-SNE, used to preserve local structural features. The results show that the three types of nodes exhibit significant clustering, indicating that the model effectively captures structural and semantic relationships. Among them, patient nodes show the most significant clustering, while the distribution of medical institutions and geographical units is more complex. These results validate the effectiveness of heterogeneous graph models in modeling relationships among multiple types of nodes, providing a semantic foundation for subsequent path modeling and attention allocation.

Fig. 3. Distribution of different types of nodes in the embedding space after t-SNE dimensionality reduction. t-SNE: t-Distributed Stochastic Neighbor Embedding.
Node Feature Initialization and Graph Convolution Design: Initial node features were derived from integrated attribute data. Patient nodes include age, gender, number of comorbidities, visit frequency in the past year, and duration of missed visits; medical institution nodes include level, service radius, bed count, and number of doctors34,35; geographic unit nodes incorporate road accessibility, ethnic composition, altitude, and per capita income. All features were z-score normalized and projected to a unified 128-dimensional space via a fully connected network. During GNN computation, the HAN model applies a structured node attention mechanism to aggregate neighborhood information, capturing fine-grained interactions between individuals and service pathways. For each layer, the attention weight between node i and its neighbor j under meta-path m is computed as follows:
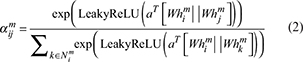
where 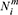 represents the adjacent set of node i under meta-path m, and a and W are trainable parameters. The multi-head attention mechanism is used to stabilize the training process, and the final node representation is obtained through multi-head aggregation.
represents the adjacent set of node i under meta-path m, and a and W are trainable parameters. The multi-head attention mechanism is used to stabilize the training process, and the final node representation is obtained through multi-head aggregation.
A two-layer HAN with 64-dimensional outputs per layer is used to enhance embedding representation and capture cross-layer dependencies. The Exponential Linear Unit (ELU) serves as the activation function, with a 0.5 dropout rate to prevent overfitting. Each node thus obtains an embedding vector integrating meta-path semantics and neighborhood interactions, providing a structure-aware input for subsequent classification.
Patient Service Utilization Classification Model Construction
This study aims to implement equitable health interventions in ethnic minority areas. It incorporates the World Health Organization’s framework of social determinants of health and identifies ethnic identity, language barriers, cultural beliefs, and geographical marginalization as key drivers of structural inequality. Particularly, in Tibetan and Lisu-populated areas like Diqing and Nujiang, the disconnect between traditional healthcare preferences and primary healthcare services often leads to institutional loss to follow-up. Therefore, this model not only identifies potentially lost-to-follow-up individuals but also incorporates variables such as ethnic composition and the ethnic matching between village doctors and patients, ensuring that the classification results reflect the dimension of cultural accessibility.
Model Structure and Input Design: After completing the graph structure construction and node embedding learning, it is necessary to apply a supervised learning mechanism to further identify the differences in patients’ behavioral patterns in the health service system. Based on the patient node embedding vectors output by the HAN model in the previous stage, this study constructed a graph attention network (GAT) classifier to complete the multi-classification recognition task of three types of service utilization behaviors: “frequent medical visitors,” “regular medical visitors,” and “potentially lost visits.”
The Anderson behavioral model serves as the theoretical basis for constructing service utilization labels, explaining influencing factors across three dimensions: predisposing, enabling, and need factors. Sex, age, and education represent predisposing factors; insurance type, income, and accessibility index are enabling factors; and the number and severity of chronic diseases reflect health needs. These factors jointly define label logic and feature vectors, guiding the classifier in distinguishing “frequent medical visitors” from “potentially lost visits.”
The model input is a patient node vector with an embedding dimension of 128, and the output is a category distribution vector of length 3, which is normalized using the softmax function. In the GAT structure, two layers of attention graph convolution are set; each layer uses eight parallel attention heads, and the output dimension of each head is 16. The ELU activation function and Dropout (with a rate set to 0.5) are used after the first layer to prevent overfitting. The second layer outputs the classification dimension, and the fully connected layer is used for decision prediction. The loss function in model training utilizes category-weighted cross-entropy to mitigate the training offset resulting from the insufficient number of samples in the “potentially lost visit” class. To further enhance the classifier’s ability to express the heterogeneity of service behaviors in the graph structure, the adjacency weight αij in the GAT model is calculated in the following form:
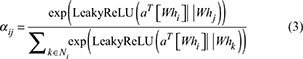
where a is a learnable attention weight vector; W is a shared linear transformation matrix; hi and hj are node embedding representation. This mechanism dynamically adjusts the aggregation strength according to the similarity between adjacent nodes, thereby improving the model’s ability to identify overlapping groups of frequent medical treatment paths and marginal behaviors of lost patients.
In this study, the dropout rate was set to 0.5, and the initial learning rate was set to 0.001, determined based on the performance of a grid search on the validation set. Specifically, dropout values were tested within the range of {0.3, 0.5, 0.7}, and it was found that a value of 0.5 achieved the highest recall and most stable validation loss for the “potentially lost” category. A comparison of learning rates within the range of {0.01, 0.001, 0.0001} revealed that 0.001 achieved the best balance between convergence speed and generalization ability.
Label Definition and Supervised Training Mechanism: The supervision signals for service model classification are derived from historical medical behavior data. Patients with an average annual visit frequency ≥ 6 and intervals ≤ 30 days are labeled as frequent visitors; those with regular but below-average annual visits as regular visitors; and those with no visits or gaps ≥ 12 months as potentially lost visitors. This labeling accounts for both visit density and long-term discontinuity to capture behavioral heterogeneity. To enhance model stability and generalization, class balance is achieved using ELU oversampling, with an 8:2 training–validation split. The model is trained using Adam (learning rate = 0.001, 200 epochs) with early stopping after 10 stagnant validation losses. Performance is evaluated by macro-average F1 and recall to address class imbalance and ensure robust multi-class prediction.
Figure 4 shows the patient service classification model based on the GAT.

Fig. 4. Patient service classification model based on GAT. GAT: graph attention network; SMOT: Synthetic Minority Oversampling Technique.
Integration of Geographic and Socioeconomic Variables
Health geography and spatial accessibility are not separate concepts in rural health service research but rather mutually supportive theoretical dimensions. Health geography emphasizes the spatially nested relationship between disease distribution, medical services, and the social environment, while spatial accessibility quantifies the physical and institutional barriers to residents’ access to services. In frontier regions like Yunnan in northwest China, with its complex terrain and concentrated ethnic populations, the two are highly coupled: plateau valleys not only prolong medical care but also reinforce institutional exclusion by restricting transportation networks. This study co-encodes road grade, elevation fluctuations, and administrative boundaries as edge weights and node attributes in a graph structure. Based on the health geography perspective that “space is social structure,” this study elevates accessibility beyond a mere distance function to a composite indicator embedded with ethnic identity, resource density, and topographical constraints.
Spatial Attribute Feature Injection Mechanism
To enhance the graph structure’s ability to represent service accessibility and regional behavioral heterogeneity, this study introduces multidimensional geographical and socioeconomic variables into the embedding and classification models to construct an extended heterogeneous graph. Geographical variables include road accessibility (shortest travel time), terrain complexity, and spatial marginality (standardized shortest distance to township or county hospitals); social variables cover ethnic identity, household registration level (village, township, county), and regional medical resource density (number of beds, number of practicing physicians). Variables are injected through a node-level attribute expansion mechanism, performing feature concatenation at both patient and geographical unit nodes to improve the model’s ability to perceive service disparities in remote ethnic minority areas.
Specifically, for the patient node, its original embedding representation vector 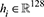 is expanded to
is expanded to 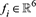 , where
, where 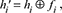 represents the six-dimensional auxiliary feature vector of the geographic unit corresponding to the patient, and the final node representation dimension is expanded to 134 dimensions. The auxiliary features are all normalized by Min-Max to avoid distribution bias interfering with attention-weight learning. To enhance the structural influence of spatial variables on the graph propagation process, a weighted adjacency adjustment mechanism is applied in the definition of edge connections. If there is a spatial connection between patient vi
and his administrative unit , the edge weight is given as:
represents the six-dimensional auxiliary feature vector of the geographic unit corresponding to the patient, and the final node representation dimension is expanded to 134 dimensions. The auxiliary features are all normalized by Min-Max to avoid distribution bias interfering with attention-weight learning. To enhance the structural influence of spatial variables on the graph propagation process, a weighted adjacency adjustment mechanism is applied in the definition of edge connections. If there is a spatial connection between patient vi
and his administrative unit , the edge weight is given as:

where dij represents the spatial distance; β is the attenuation coefficient (set to 0.15); sj is the medical resource index of the region; and γ is the normalized mapping function used to suppress gradient instability caused by extreme resource distribution. In this way, the model not only relies on the graph structure itself during information dissemination but also dynamically adjusts the dissemination intensity to reflect the impact of spatial accessibility and uneven resource distribution.
Attribute-Sensitive Aggregation and Edge Region Specialization Modeling
Considering the structural differences and semantic heterogeneity between the applied geo-social features and the original embedded features, the classification model performs channel encoding on the input vector and applies a dual-channel perception layer. The first channel receives the structural embedding generated by HAN or GAT, and the second channel specifically processes the injected geo-social features. The two channels are fused through the attention-gating mechanism, and the fusion weights are learned as follows:


where W 1 and W 2 are linear transformation matrices; ⊙ is the Hadamard product; σ is the Sigmoid function; and the final output fusion vector Z is used as input for subsequent classification tasks. While maintaining the dominant position of the main image information, this structure gives adjustable weights to spatial edge variables through a gating mechanism, which is suitable for identifying service variables with significant behavioral heterogeneity in areas such as ethnic minority settlements and complex plateau terrain.
During the model training phase, regional grouping supervision indicators are set, and the performance of each regional model is guided by applying geographical stratification supervision loss. Specifically, based on the original cross-entropy loss, a regularization term is added to minimize cross-regional prediction errors, thereby reducing the prediction performance gap between high-resource and low-resource areas during the model training process. The following regularization loss function implements this mechanism:

where G is the set of all region groups, F1g is the validation set F1 value of the g-th region, and 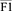 is the mean F1 of all regions. The final total loss function is:
is the mean F1 of all regions. The final total loss function is:

where λ is the weight factor, which is set to 0.1. This mechanism encourages the model to prioritize regional fairness while optimizing the overall situation, thereby improving prediction stability and explanatory power in areas with severe uneven medical resources.
Figure 5 illustrates the distribution of three patient types (high-frequency patients, regular patients, and potential lost contacts) across three geo-social characteristics: road accessibility, altitude, and economic level. The X-axis represents the corresponding characteristic value, and the Y-axis is the sample frequency. Overall, those who frequently seek medical treatment (red) have a higher mean road accessibility, indicating that convenient transportation may promote high-frequency medical treatment behavior. The road feasibility of potential lost patients is relatively dense at around 0.06, revealing that the disadvantaged groups in road traffic are prone to be out of the service system; the altitudes of the three types of patients are all distributed between 2,000 and 4,000, reflecting that the patients are at a higher altitude; in terms of economic level, the economic level of potential lost patients is relatively dense at around 0.06, which is lower than that of regular and frequent medical treatment seekers, revealing that economically disadvantaged groups are more likely to be out of the service system.

Fig. 5. Distribution of patients of different categories in three typical geographical and social characteristics.
Service Path Optimization Suggestion Generation
After completing the classification of high-frequency medical patients and potential lost follow-up groups, the health service utilization graph is further structurally analyzed to identify nodes and paths that play a key intermediary role or form structural bottlenecks in the service network and then provide structurally reasonable resource allocation suggestions. First, the centrality index of each type of node (patient, medical institution, and geographic unit) in the graph is calculated, including degree centrality, eigenvector centrality, and betweenness centrality. Among them, betweenness centrality is used to measure the transit capacity of the node in the patient service path, expressed as:

where σst represents the number of shortest paths from node s to node t and σst (v) represents the number of paths passing through node v. Based on this, the top 10% of medical institution nodes and geographic unit nodes in terms of centrality are extracted and marked as “core service nodes.” At the same time, the intermediate geographic units along the path between frequent medical patients and the core service nodes are selected, and their average path length and betweenness centrality in the entire graph are calculated to identify the “key service corridors” that form bottlenecks.
At the edge connection level, the edge load index is applied to measure the congestion degree of the edge, as shown in formula (10):

This indicator measures the importance of the edge e in the shortest path to all nodes. The internal edge load distribution is calculated for the subgraph of the frequent medical treatment group and the subgraph of the potential lost visit group. By comparing their edge density and average path length, it is determined whether the service connection poses a risk of centralization or spatial fracture. The edges with excessively high load and the connections with path spans greater than the average value are marked to form a set of “weak service connections.”
Figure 6 illustrates the identification of key institutions and spatial path pressure analysis within the healthcare service network. The radar chart on the left characterizes five major healthcare institutions using degree centrality, eigenvector centrality, and betweenness centrality. The results show that Hospitals-8 and -19 perform exceptionally well across multiple dimensions, exhibiting high connectivity and bridging capabilities. The heatmap on the right reflects the edge load between geographical units; darker colors represent higher service traffic. Units 6 and 9 show a load exceeding 0.8, forming a significant bottleneck. Overall, some institutions and paths experience high service pressure, providing a basis for regional collaborative optimization and intervention at key nodes.

Fig. 6. Analysis of key institution identification and spatial path pressure in optimizing medical service network.
Health Service Optimization Modeling Path
The data for this study come from a special survey on the utilization of health services by the rural elderly conducted in 2023 in four autonomous prefectures (Dali, Lijiang, Diqing, and Nujiang) in northwestern Yunnan Province. The survey subjects were rural residents of ethnic minorities aged <60 years. The study focused on individuals with two or more chronic diseases (such as hypertension, diabetes, coronary heart disease [CHD], stroke, and chronic obstructive pulmonary disease [COPD]). Data collection covered demographic characteristics, family economic status, health behaviors (smoking, drinking, exercise, nutrition, sleep, etc.), and medical service utilization characteristics (outpatient visits, hospitalizations, frequency of visits every 2 weeks, etc.).
Spatial coordinates of patients’ residences, administrative units, and the distribution of medical institutions were also integrated for graph structure construction and GNN model training. Minors, non-rural residents, individuals with severe cognitive impairment, and those who refused to participate in the survey were excluded. The sample is regionally representative but does not fully cover the Dulongjiang River basin in Nujiang. To evaluate the model’s generalization ability, stratified 5-fold cross-validation was used, dividing the training and validation sets by geographical unit to ensure that data from the same township did not overlap, thus simulating cross-regional deployment. The results show that the macroscopic F1 standard deviation is ±0.021, indicating that the model is stable across different sub-regions.
Service Accessibility Index
The service accessibility index is calculated using patients’ home and institution coordinates from medical records, corrected with high-resolution geographic data. Based on 1:50,000 terrain and road grade maps, a weighted shortest path algorithm adjusts for elevation and road accessibility while removing abnormal points. Average travel time for each patient’s visits over the past year is aggregated at the village level to map regional accessibility. Higher scores indicate greater spatial barriers, typical in high-altitude and sparsely populated areas, reflecting uneven basic service distribution.
Figure 7 analyzes the access to medical services in the four prefectures of northwestern Yunnan (Dali, Lijiang, Diqing, and Nujiang) from the perspective of spatial accessibility. The X-axis of the left figure is the village altitude (meters), and the Y-axis is the accessibility index (unit: minutes). In Diqing (approximately 3,600 ± 400 meters above sea level) and Nujiang (with an average altitude of about 2,700 meters), the time it takes to receive medical services is significantly higher than in low-altitude areas, such as Dali, indicating that patients in plateau areas face more pronounced transportation obstacles. The right figure is a box plot of medical accessibility in each state, with the Y-axis representing access time. It can be seen that the average accessibility index of Diqing is as high as 68 min, which is much higher than Dali’s 29 min, and its internal differences are also greater. Figure 8 quantitatively reveals the uneven impact of regional geographical differences on medical accessibility, providing intuitive evidence for understanding the problem of primary medical accessibility in border multiethnic areas.

Fig. 7. Spatial differences in medical accessibility among 50 administrative villages.

Fig. 8. Performance of service utilization intensity ratio in different disease combinations and age groups. CHD: congested heart disease; CKD: chronic kidney disease; COPD: chronic obstructive pulmonary disease.
Service Utilization Intensity Ratio
Based on individual medical data, the frequency of service utilization by patients in a given year is counted by the level of medical institution, and health needs are quantified in combination with the number of illnesses and previous hospitalization records. A theoretical treatment interval is set for each type of disease combination (refer to the national primary care chronic disease management standards), and the expected service intensity is estimated by constructing a hierarchical linear model. The ratio of actual service intensity to the model expectation is then calculated as an indicator of the service utilization intensity ratio. Those with significant deviations in the ratio are identified as potential service mismatch objects, particularly for individuals with complex comorbidities who receive insufficient medical treatment or those with mild conditions but frequent visits to high-level hospitals, providing an objective basis for identifying resource utilization deviations.
Figure 8 illustrates the utilization rates of different chronic disease combinations and elderly age groups in northwest Yunnan, reflecting the service matching status of multimorbid older adults. Overall, most combinations show slightly lower-than-expected visit frequencies, indicating insufficient service coverage. The “Cataract + Diabetes” group has the lowest utilization rate (0.645), suggesting poor attention to vision-related complications. In contrast, the “Multimorbidity (>3+)” group shows a high rate (1.138), reflecting adequate service matching and a resource bias toward severe cases. The “COPD + CHD” combination (1.152) indicates mild overuse, likely due to overlapping respiratory–cardiovascular symptoms. By age, utilization rises to a peak of 1.22 among those aged 76 to 80 years but declines to 0.68 in those >86 years, implying reduced access due to mobility and care constraints. These findings highlight structural imbalances in regional resource allocation and the need for age- and disease-specific service optimization.
Service Path Rationality Score
Each patient’s continuous medical records are mapped to a heterogeneous graph, and the service path is extracted. The average number of hops, the shortest path deviation, and the frequency of cross-administrative-level medical treatment are calculated. The spatial adjacency matrix and service level mapping table between medical institutions are used to evaluate the structural optimization of all service paths. If the path repeatedly crosses county lines, unnecessary level upgrades and frequent changes of institutions occur, and the rationality score is reduced. This method helps to identify irrational medical behavior caused by poor referral processes, information islands, or medical preferences. It is particularly important to evaluate the rationality of the path, especially in the context of high costs of cross-regional medical treatment in plateau areas.
Table 1 shows the rationality evaluation results of typical medical treatment paths. Combined with the average number of hops, path deviation, frequency of cross-county medical treatment, unnecessary level upgrade, and other indicators, the rationality score is calculated and evaluated. It can be seen that the medical treatment path with path ID P015 performs best, with an average number of hops of only 1.2, a shortest path deviation of 8.7%, no cross-county medical treatment, and no unnecessary level upgrade, resulting in a rationality score of 92.3, which is evaluated as “excellent.” In contrast, the P042 path has significant problems, with an average number of hops of 4.1, a deviation of 72.5% from the shortest path, six cross-county medical treatments, three unnecessary level upgrades, and a rationality score of only 41.2, which is a “high-risk” path, indicating that its path planning is seriously unreasonable; P102 performs above average, with a rationality score of 78.9, which is “good,” and there are significant differences in service accessibility and rationality between different paths.
| Pathway ID | Avg. steps | Shortest path deviation (%) | Cross-county visits | Unnecessary level escalations | Rationality score* | Evaluation result |
| P001 | 2.8 | 34.2 | 3 | 1 | 68.5 | Moderate |
| P015 | 1.2 | 8.7 | 0 | 0 | 92.3 | Excellent |
| P042 | 4.1 | 72.5 | 6 | 3 | 41.2 | High Risk |
| P087 | 3.3 | 48.6 | 4 | 2 | 56.8 | Low |
| P102 | 2.1 | 22.3 | 1 | 1 | 78.9 | Good |
| * Data are significant. ID: identification. |
||||||
Service Frequency and Health Needs Matching Rate
For elderly people with two or more chronic diseases, a disease combination-service frequency mapping model is constructed. The model input includes the number of comorbidities, core disease combinations (such as diabetes and hypertension, COPD and CHD, etc.), disease duration, and previous hospitalizations and outputs the expected range of individual annual service frequencies. The actual number of visits is compared with this interval, and those with a higher number are classified as having “over-dependence.” In comparison, those with a lower number are considered to have a “potential loss to follow-up.” This indicator is further adjusted based on the individual’s demographic and social attributes to enhance the sensitivity of assessing matching service utilization with health status and guide targeted health interventions.
Table 2 presents the matching of different chronic disease combinations in terms of medical service utilization, measuring the rationality of services through indicators such as the number of patients, expected frequency of visits, actual matching rate, and utilization intensity classification ratio.
| Disease combination | Number of patients | Expected range [L, U] | Matching rate (%) | Classification proportion (%)* |
| Hypertension + Diabetes | 142 | [5.5, 7.2] | 85.9 | 20 / 75 / 5 |
| CHD + Stroke | 87 | [7.0, 9.0] | 78.2 | 35 / 58 / 7 |
| COPD + Asthma | 63 | [6.5, 8.0] | 82.5 | 25 / 68 / 7 |
| CKD + Diabetes | 58 | [8.0, 10.5] | 72.4 | 42 / 50 / 8 |
| Hypertension + Hyperlipidemia | 127 | [4.8, 6.0] | 88.2 | 15 / 80 / 5 |
| Peptic Ulcer + Diabetes | 49 | [5.2, 7.0] | 83.7 | 22 / 72 / 6 |
| Cataract + Diabetes | 92 | [3.5, 4.8] | 79.3 | 12 / 65 / 23 |
| COPD + CHD | 54 | [7.5, 9.5] | 75.9 | 38 / 55 / 7 |
| Stroke + Hypertension | 103 | [6.5, 8.8] | 76.7 | 33 / 60 / 7 |
| Multimorbidity (3+) | 118 | [9.0, 11.5] | 68.6 | 46 / 48 / 6 |
| * indicates that the data has statistical significance. CHD: chronic heart disease; COPD: chronic obstructive pulmonary disease; CKD: chronic kidney disease. |
||||
Overall, the service matching rate of most disease combinations remains at a high level. For example, the matching rate of the combination of “hypertension + hyperlipidemia” reaches 88.2%, indicating that the frequency of visits for most patients falls within a reasonable range [4.8, 6.0], and 80% of the patients in this classification ratio are classified as having “normal” utilization levels. In contrast, the matching rate of the “multi-disease combination (3+)” is only 68.6%, the lowest value, and the over-dependence rate is as high as 46%, highlighting the significant lack of service access for patients with multiple chronic diseases, which may be affected by functional impairment, transportation accessibility, or lack of service continuity.
In addition, the matching rate for the “chronic kidney disease + diabetes” combination is also low, at only 72.4%, and the proportion of over-dependence is as high as 42%, suggesting that active management and service resource allocation should be strengthened in these high-risk groups. Therefore, the data in Table 2 reveal significant differences in the rationality of service utilization among different disease groups, providing an empirical basis for the formulation of personalized intervention strategies.
Adequacy of Spatial Resource Coverage
This indicator quantifies the spatial accessibility of medical resources within a specific geographical unit through buffer zone analysis. With each household as the center, three equidistant buffer zones of 5 km, 10 km, and 15 km are established to count the number of medical institutions and their service capacities (number of beds, staff size, annual outpatient volume, etc.). The slope and road grade correction factors are applied to the mountain samples for weighted adjustment. Finally, a per-population medical resource coverage index is formed. If areas with low resource coverage overlap with groups with high service demand or high terrain obstacles, they are identified as “high-risk medical areas.” Providing spatial decision support for the construction of new medical sites or the implementation of mobile service vehicles.
Table 3 presents the coverage of medical resources across different geographical units and assesses their risk levels by combining population density, coverage index, and terrain correction coefficient. For example, G07 has a high population density (86.2 people/km²), a 5 km coverage index of 0.92, and a small terrain impact (coefficient 1.0) and is therefore rated as low risk. In contrast, G18 and G29 have low population densities (28.7 and 38.9, respectively), 5 km coverage indexes of only 0.31 and 0.42, respectively, and complex terrain (coefficients as high as 1.8 and 2.1, respectively), both of which are considered high-risk areas. Overall, it reflects that resource coverage in mountainous or remote areas is insufficient and needs to be optimized.
Performance Comparison With Traditional Models
To systematically evaluate the effectiveness of the proposed Hierarchical Attention Network-Graph Attention Network (HAN-GAT) heterogeneous GNN model in classifying the service utilization of elderly populations with chronic disease comorbidities in rural northwest Yunnan, this paper selected five traditional models as baselines for comparative experiments. These models include logistic regression (LR), random forest (RF), XGBoost, K-means clustering, and multilayer perceptron (MLP), covering the mainstream paradigms of statistical learning, ensemble methods, and unsupervised techniques.
The data in Table 4 reveal the significant performance advantages of the HAN-GAT model. First, in terms of overall accuracy, HAN-GAT achieves a Macro-F1 score of 0.83, which is higher than that of the traditional model, XGBoost (0.76). This is because its graph structure embedding mechanism dynamically captures patient-institution interactions (such as referral paths), breaking through the traditional method’s reliance on static attributes. Although XGBoost performs better in F1 for frequent medical visitors (0.79), HAN-GAT further improves to 0.85, indicating that it is more sensitive to high-frequency behavior patterns. Second, in terms of marginal group identification, the recall rate of potential lost contacts of HAN-GAT is 0.89, much higher than LR (0.58) and MLP (0.61), proving that the model effectively integrated geographic social variables and solved the blind spot caused by ignoring temporal behavior of K-means (recall rate is only 0.52). In summary, data-driven HAN-GAT accurately locates high-risk areas in resource optimization and promotes intervention measures such as the establishment of mobile medical points.
Conclusion
Based on the health service utilization of elderly patients with chronic diseases in rural ethnic areas of northwest Yunnan, this study constructs a heterogeneous graph integrating patients, medical institutions, and geographic units. Using a GNN, it models medical behavior paths, identifies frequent visitors and potentially lost visits, and proposes service optimization strategies based on node centrality and path rationality. Results show that the GNN effectively captures behavioral structures and path heterogeneity, detects service mismatches, and enhances targeted resource allocation. By integrating spatial, ethnic, and health factors, the model demonstrates strong adaptability in complex contexts. Limitations include a restricted data scope and partial reliance on retrospective self-reports. Future work will expand sampling, incorporate real-time multi-source data, and improve model generalization to better support precise health service optimization in underdeveloped regions.
Contributors
Jing Zhang conceptualized this work. Haitao Fan wrote the manuscript. Jing Zhang and Haitao Fan conducted the review of the first draft and response to reviewer comments.
Data Availability Statement (DAS), Data Sharing, Reproducibility, and Data Repositories
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Application of AI-Generated Text or Related Technology
None.
References
- Quiñones AR, Hwang J, Heintzman J, Huguet N, Lucas JA, Schmidt TD, et al. Trajectories of chronic disease and multimorbidity among middle-aged and older patients at community health centers. JAMA Netw Open. 2023;6(4):e237497. https://doi.org/10.1001/jamanetworkopen.2023.7497
- Caraballo C, Herrin J, Mahajan S, Massey D, Lu Y, Ndumele CD, et al. Temporal trends in racial and ethnic disparities in multimorbidity prevalence in the United States, 1999–2018. Am J Med. 2022;135(9):1083–92.e14. https://doi.org/10.1016/j.amjmed.2022.04.010
- Lin S, Fang L. Chronic care for all? The intersecting roles of race and immigration in shaping multimorbidity, primary care coordination, and unmet health care needs among older Canadians. J Gerontol Series B. 2023;78(2):302–18. https://doi.org/10.1093/geronb/gbac125
- Gao Q, Prina AM, Ma Y, Aceituno D, Mayston R. Inequalities in older age and primary health care utilization in low-and middle-income countries: a systematic review. Int J Health Serv. 2022;52(1):99–114. https://doi.org/10.1177/00207314211041234
- Ronaldson A, De La Torre JA, Broadbent M, Ashworth M, Armstrong D, Bakolis I, et al. Ethnic differences in physical and mental multimorbidity in working age adults with a history of depression and/or anxiety. Psychol Med. 2023;53(13):6212–22. https://doi.org/10.1017/S0033291722003488
- Watkinson RE, Sutton M, Turner AJ. Ethnic inequalities in health-related quality of life among older adults in England: secondary analysis of a national cross-sectional survey. Lancet Public Health. 2021;6(3):e145–54. https://doi.org/10.1016/S2468-2667(20)30287-5
- Mols RE, Bakos I, Christensen B, Horváth-Puhó E, Løgstrup BB, Eiskjær H. Influence of multimorbidity and socioeconomic factors on long-term cross-sectional health care service utilization in heart transplant recipients: a Danish cohort study. J Heart Lung Transpl. 2022;41(4):527–37. https://doi.org/10.1016/j.healun.2022.01.006
- Quiñones AR, Valenzuela SH, Huguet N, Huguet N, Ukhanova M, Marino M, et al. Prevalent multimorbidity combinations among middle-aged and older adults seen in community health centers. J Gen Intern Med. 2022;37(14): 3545–53. https://doi.org/10.1007/s11606-021-07198-2
- Suls J, Bayliss EA, Berry J, Bierman AS, Chrischilles EA, Farhat T, et al. Measuring multimorbidity: selecting the right instrument for the purpose and the data source. Med Care. 2021;59(8):743–56. https://doi.org/10.1097/MLR.0000000000001566
- Sheng JQ, Xu D, Hu PJH, Li L, Huang TS. Mining multimorbidity trajectories and co-medication effects from patient data to predict post–hip fracture outcomes. ACM Trans Manag Inf Syst. 2024;15(2):1–24. https://doi.org/10.1145/3665250
- Woodman RJ, Mangoni AA. A comprehensive review of machine learning algorithms and their application in geriatric medicine: present and future. Aging Clin Exp Res. 2023;35(11):2363–97. https://doi.org/10.1007/s40520-023-02552-2
- Chowdhury S, Chen Y, Li P, Rajaganapathy S, Wen A, Ma X, et al. Stratifying heart failure patients with graph neural network and transformer using Electronic Health Records to optimize drug response prediction. J Am Med Inf Assoc. 2024;31(8):1671–81. https://doi.org/10.1093/jamia/ocae137
- Amini M, Bagheri A, Paulus MP, Delen D. Multimorbidity in neurodegenerative diseases: a network analysis. Inform Health Soc Care. 2024;49(3–4):212–26. https://doi.org/10.1080/17538157.2024.2405869
- Lu H, Uddin S, Hajati F, Moni MA, Khushi M. A patient network-based machine learning model for disease prediction: the case of type 2 diabetes mellitus. Appl Intell. 2022;52(3):2411–22. https://doi.org/10.1007/s10489-021-02533-w
- Yew PY, Devera R, Liang Y, El Khalifa RA, Sun J, Chi N, et al. Unraveling the multiple chronic conditions patterns among people with Alzheimer’s disease and related dementia: a machine learning approach to incorporate synergistic interactions. Alzheimers Dement. 2024;20(7):4818–27. https://doi.org/10.1002/alz.13923
- Walsh B, Fogg C, England T, Brailsford S, Roderick P, Harris S, et al. Impact of frailty in older people on health care demand: simulation modelling of population dynamics to inform service planning. Health Soc Care Deliv Res. 2024;12(44):1–140. https://doi.org/10.3310/LKJF3976
- Argentieri MA, Xiao S, Bennett D, Winchester L, Nevado-Holgado AJ, Ghose U, et al. Proteomic aging clock predicts mortality and risk of common age-related diseases in diverse populations. Nat Med. 2024;30(9):2450–60. https://doi.org/10.1038/s41591-024-03164-7
- Sayed N, Huang Y, Nguyen K, Krejciova-Rajaniemi Z, Grawe AP, Gao T, et al. An inflammatory aging clock (iAge) based on deep learning tracks multimorbidity, immunosenescence, frailty and cardiovascular aging. Nat Aging. 2021;1(7):598–615. https://doi.org/10.1038/s43587-021-00082-y
- Phan NMT, Chen L, Chen CH, Peng WH. FastRx: exploring fastformer and memory-augmented graph neural networks for personalized medication recommendations. ACM Trans Intell Syst Technol. 2024;15(6):1–21. https://doi.org/10.1145/3696111
- Hernández-Arango A, Arias MI, Pérez V, Chavarría LD, Jaimes F. Prediction of the risk of adverse clinical outcomes with machine learning techniques in patients with noncommunicable diseases. J Med Syst. 2025;49(1):1–13. https://doi.org/10.1007/s10916-025-02140-z
- Jørgensen IF, Haue AD, Placido D, Hjaltelin JX, Brunak S. Disease trajectories from healthcare data: methodologies, key results, and future perspectives. Annu Rev Biomed Data Sci. 2024;7(1):251–76. https://doi.org/10.1146/annurev-biodatasci-110123-041001
- Anghel I, Cioara T, Bevilacqua R, Barbarossa F, Grimstad T, Hellman R, et al. New care pathways for supporting transitional care from hospitals to home using AI and personalized digital assistance. Sci Rep. 2025;15(1):1–12. https://doi.org/10.1038/s41598-025-03332-w
- Zhang S, Strayer N, Vessels T, Choi K, Wang GW, Li Y, et al. PheMIME: an interactive web app and knowledge base for phenome-wide, multi-institutional multimorbidity analysis. J Am Med Inform Assoc. 2024;31(11):2440–6. https://doi.org/10.1093/jamia/ocae182
- Gill SK, Karwath A, Uh HW, Cardoso VR, Gu Z, Barsky A, et al. Artificial intelligence to enhance clinical value across the spectrum of cardiovascular healthcare. Eur Heart J. 2023;44(9):713–25. https://doi.org/10.1093/eurheartj/ehac758
- Demiray O, Gunes ED, Kulak E, Dogan E, Karaketir SG, Cifcili S, et al. Classification of patients with chronic disease by activation level using machine learning methods. Health Care Manag Sci. 2023;26(4):626–50. https://doi.org/10.1007/s10729-023-09653-4
- Damluji AA, Nanna MG, Rymer J, Kochar A, Lowenstern A, Baron SJ, et al. Chronological vs biological age in interventional cardiology: a comprehensive approach to care for older adults: JACC family series. JACC Cardiovasc Interv. 2024;17(8):961–78. https://doi.org/10.1016/j.jcin.2024.01.284
- Sultana N, Saimon SI, Islam I, Abir SI, Hossain MS, AI Shiam SA, et al. Artificial intelligence in multi-disease medical diagnostics: an integrative approach. J Computer Sci Technol Stud. 2025;7(1):157–75. https://doi.org/10.32996/jcsts.2025.7.1.12
- Wang JH, Soo Goh JO, Chang YL, Chen SC, Li YY, Yu YP, et al. Multimorbidity and regional volumes of the default mode network in brain aging. Gerontology. 2022;68(5):488–97. https://doi.org/10.1159/000517285
- Yao Z, Liu B, Wang F, Sow D, Li Y. Ontology-aware prescription recommendation in treatment pathways using multi-evidence healthcare data. ACM Trans Inf Syst. 2023;41(4):1–29.
- Zheng Y, Zhang T, Yang S, Wang F, Zhang L, Liu Y. Using machine learning to predict the probability of incident 2-year depression in older adults with chronic diseases: a retrospective cohort study. BMC Psychiatry. 2024;24(1):1–11. https://doi.org/10.1186/s12888-024-06299-6
- Omuya H, Nickel C, Wilson P, Chewning B. A systematic review of randomised-controlled trials on deprescribing outcomes in older adults with polypharmacy. Int J Pharm Pract. 2023;31(4): 349–68. https://doi.org/10.1093/ijpp/riad025
- Bressler T, Song J, Kamalumpundi V, Chae S, Song H, Tark A. Leveraging artificial intelligence/machine learning models to identify potential palliative care beneficiaries: a systematic review. J Gerontol Nurs. 2025;51(1):7–14. https://doi.org/10.3928/00989134-20241210-01
- Van Heerden PV, Beil M, Guidet B, Sviri S, Jung C, de Lange D, et al. A new multi-national network studying Very old Intensive care Patients (VIPs). Anaesthesiol Intensive Ther. 2021;53(4):290–5. https://doi.org/10.5114/ait.2021.108084
- Karatas M, Zare Z, Zheng YJ. Transforming preventive healthcare with machine learning technologies. J Oper Intell. 2025;3(1):109–25. https://doi.org/10.31181/jopi31202538
- Tenepalli D, Navamani TM. A systematic review on IoT and machine learning algorithms in e-healthcare. Int J Comput Digit Syst. 2024;16(1):279–94. https://doi.org/10.12785/ijcds/160122
Copyright Ownership: This is an open-access article distributed in accordance with the Creative Commons Attribution Non-Commercial (CC BY-NC 4.0) license, which permits others to distribute, adapt, enhance this work non-commercially, and license their derivative works on different terms, provided the original work is properly cited and the use is non-commercial. See: http://creativecommons.org/licenses/by-nc/4.0. The authors of this article own the copyright.